LegalEase AI
Self-hosted legal discovery platform for messy, sensitive data.
Overview
LegalEase AI is a self-hosted workspace built for legal teams, investigators, and anyone who has to wrestle with massive piles of unstructured evidence like PDFs, videos, audio, and exports from forensic tools.
It grew out of frustration with cloud-locked legal tech that trades privacy for convenience. I wanted something fast, local-first, and transparent. So I built it: a full end-to-end stack that turns terabytes of raw evidence into structured, searchable context all without data ever leaving your machine.
Problem
Legal discovery is chaos: mixed file formats, poor metadata, and sensitive material that can’t legally be uploaded anywhere. Most tools either oversimplify or rely on expensive hosted APIs, which creates compliance and cost problems. I needed a way to search, summarize, and reason across huge datasets completely offline without losing modern AI capabilities.
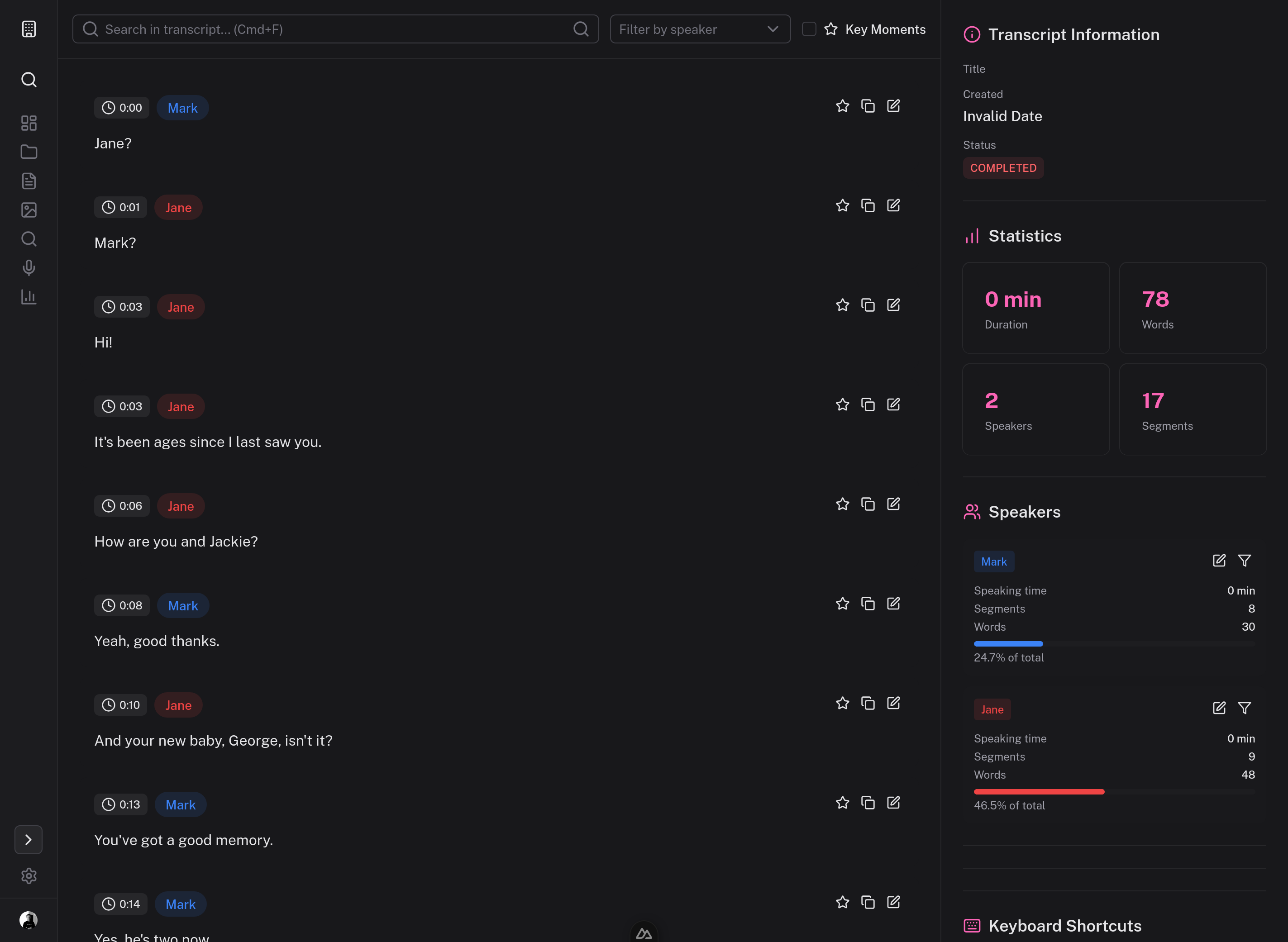
Solution
LegalEase couples a FastAPI + Celery backend with a Nuxt 4 dashboard, shipping a fully-contained environment using Docker and mise. It automates everything from OCR to RAG-based search:
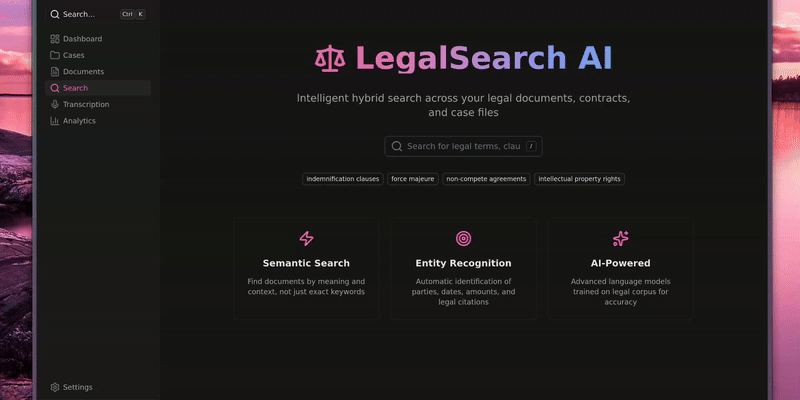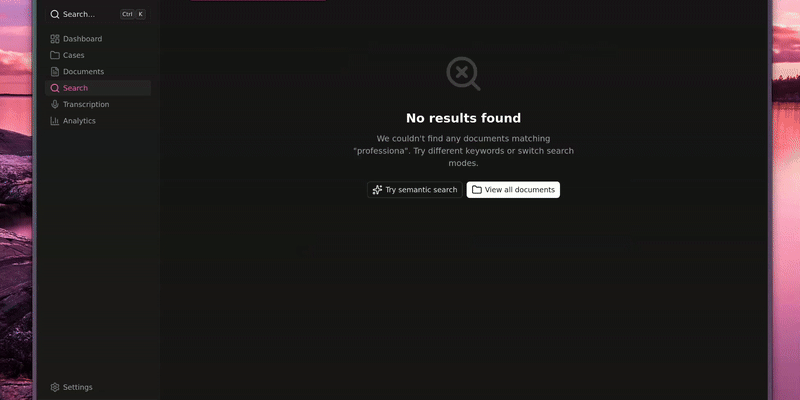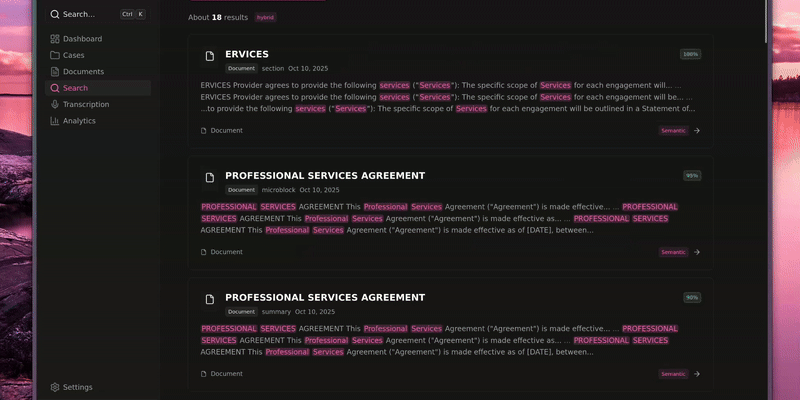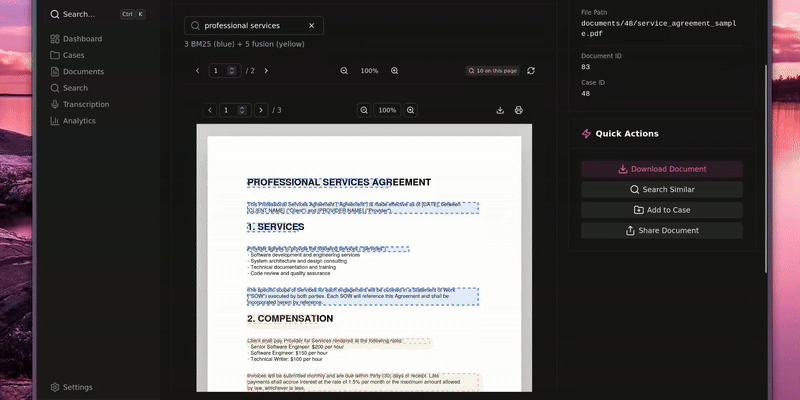
- Docling-based parsing and OCR to turn thousands of PDFs and images into hierarchical chunks.
- Hybrid retrieval combining BM25 + dense vectors in Qdrant for both keyword and semantic search.
- Audio/video transcription via WhisperX with automatic fallbacks and diarization support.
- Local LLM analysis through Ollama models for summaries, timelines, and speaker stats.
- Forensic export support for Cellebrite / AXIOM evidence folders.
- Entirely air-gapped operation — only the initial model/container pulls touch the network.
The result: a single command (mise run up) spins up a complete AI-ready research environment with databases, object storage, GPU-aware workers, and a clean dashboard for review.
Challenges & Lessons
Getting high-accuracy transcriptions and search performance at scale (while staying 100% local) was brutal. GPU scheduling, OCR throughput, and hybrid search indexing all needed to cooperate. I learned to balance practical engineering (async pipelines, caching, retry logic) with research-grade experimentation (RAG tuning, embedding hybrids).
It also taught me the value of “honest defaults” — shipping with good baseline models and clear docs beats adding more knobs.
Impact
- Processes 20 TB+ of discovery data reliably on commodity hardware.
- Reduces document-review time from hours to minutes.
- Enables small legal teams to use advanced AI workflows without cloud dependencies or subscription costs.
- Inspired the foundation for my later R&D into local retrieval and evidence intelligence.
Reflection
LegalEase is what happens when you mix legal empathy with dev-ops stubbornness. It’s privacy-first, GPU-optional, and unapologetically local — built to prove that AI doesn’t have to live behind someone else’s API. It remains one of my proudest builds and the base for several spin-off tools in my stack.
Tech Stack
Python, FastAPI, Celery, Nuxt 4, Vue 3, TypeScript, Docker, Qdrant, PostgreSQL, MinIO, Redis, Ollama, Docling, WhisperX, mise